The Goal
In this tutorial, I'll go over some example usages of the Python face_recognition library to:
- Detect faces in images
- Detect facial features on a detected face (like eyebrows and nose)
- Check for matches of detected faces
All images and code snippets are provided on this post along with step-by-step instructions and explanations as to what is going on. This tutorial is aimed towards Windows 10 but Linux and macOS users will most likely find this easier as they can skip some of the prerequisites.
Here are some relevant links for face_recognition if you need/want them:
- Documentation: face-recognition.readthedocs.io
- Source code: github.com/ageitgey/face_recognition
- PyPI: pypi.org/project/face-recognition
Installing The "face_recognition" Library
Prerequisites (Windows)
To install the face_recognition library on Windows you will need the following installed:
- CMake
- Visual Studio C++ build tools
If you do not have these, you will get errors like,
CMake must be installed to build the following extensions: _dlib_pybind11
Which is telling you that CMake isn't installed, or,
You must use Visual Studio to build a python extension on windows. If you
are getting this error it means you have not installed Visual C++. Note
that there are many flavours of Visual Studio, like Visual Studio for C#
development. You need to install Visual Studio for C++.
Which is telling you that you need Visual Studio C++ build tools.
CMake
To install CMake, go to cmake.org/download/ and download the appropriate installer for your machine. I am using 64bit Windows 10 so I will get cmake-<version>-win64-x64.msi. After downloading the setup file, install it.
While installing CMake, add CMake to the system PATH environment variable for all users or the current user so it can be found easily.
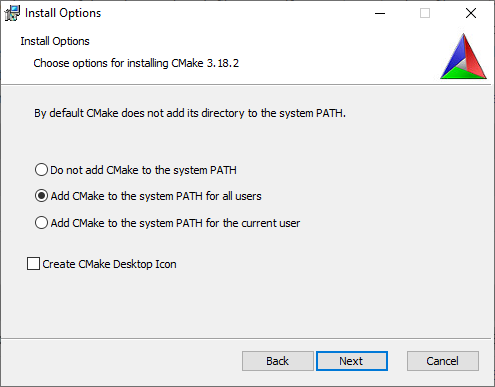
After the installation is complete, open a terminal and execute cmake. This should show the usage for CMake. If it did not, make sure you selected the option to add it to the PATH environment variable.
You will need to close and re-open your terminal/application for the PATH variable to update so the
cmakebinary can be identified.
Visual Studio C++ Build Tools
Unlike Linux, C++ compilers for Windows are not included by default in the OS. If we visit the WindowsCompilers page on the Python wiki we can see there is information on getting a standalone version of Visual C++ 14.2 compiler without the need for Visual Studio. If we visit the link from that wiki section, we will be brought to a Microsoft download page. On this download page, you will want to download "Build Tools for Visual Studio 2019".
When vs_buildtools__<some other stuff>.exe has downloaded, run the exe and allow it to install a few things before we get to the screen below. When you get to this screen, make the selections I have:
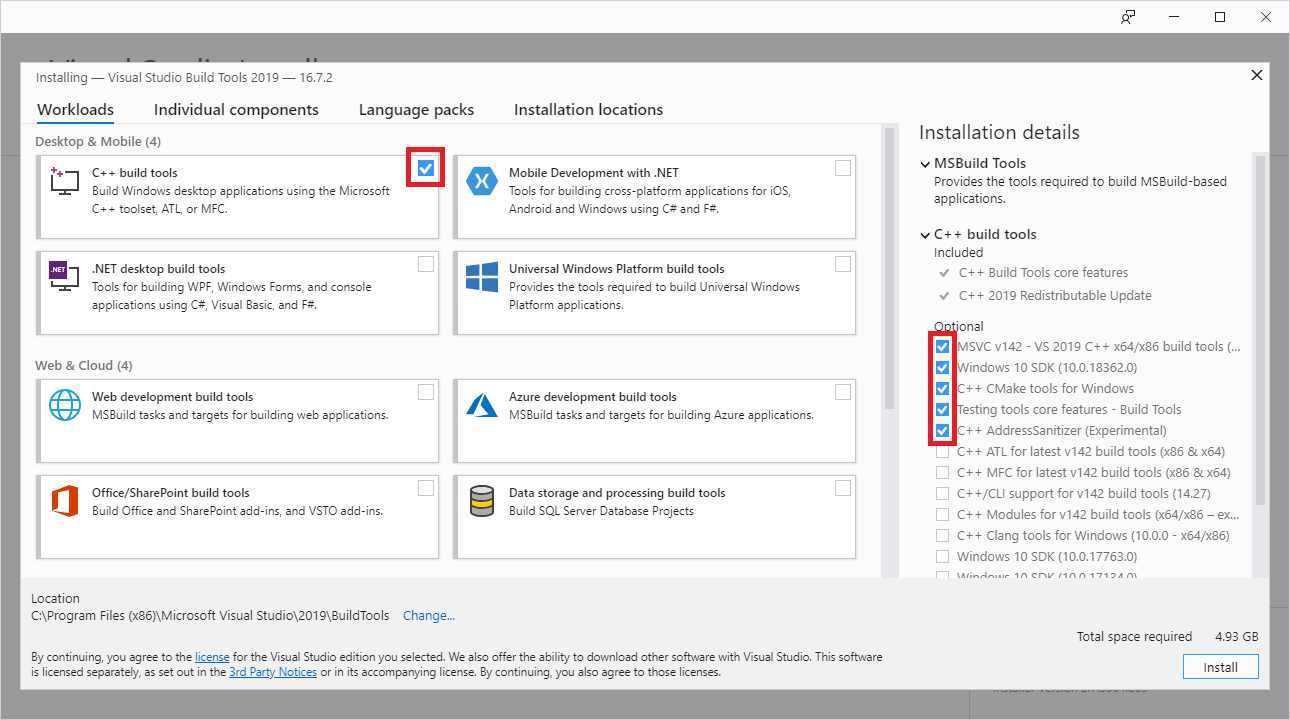
After clicking "Install", wait for the installation to complete and restart.
Now that CMake and the required build tools are installed, we can then continue to installing the face_recognition library.
Installing face_recognition and Verifying The Installation
To install the face_recognition library, execute the following in a terminal:
python -m pip install face-recognition
This might take a bit longer to install than usual as dlib needs to be built using the tools installed from above. To validate that the library was installed successfully, try to import the library in Python using the following:
import face_recognition
No errors should be raised.
Installing PIL
For this tutorial, we will also be using Pillow / PIL which will help us crop and draw on images. This is not required to use the face_recognition library but will be required in this tutorial to prove/show results. To install it, execute the following:
python -m pip install Pillow
To validate the library was installed, try to import PIL in Python using the following:
import PIL
No errors should be raised.
Detecting A Face In An Image
Now that we have set the face_recognition library and PIL up, we can now start detecting faces. To start off, we will detect a face in an image with just one person.

First, we want to import face_recognition and some helpers from PIL.
import face_recognition
from PIL import Image, ImageDraw
Now load your image using face_recognition.load_image_file.
image = face_recognition.load_image_file('single-person.jpg')
image now contains our image in a format that face_recognition can detect faces with. To identify the location of the face in this image, call face_recognition.face_locations and pass the image.
face_locations = face_recognition.face_locations(image)
face_locations will now contain a list of face locations. Each face location is a tuple of pixel positions for (top, right, bottom, left) - we need to remember this for when we use it later.
Since there is only one face in this image, we would expect there to be only one item in this list. To check how many faces were detected, we can get the length of the list.
amount = len(face_locations)
print(f'There are {amount} face locations')
For the example image I have provided above and am using for this tutorial, this has told me there was one face detected.
To get the location of this face to use later, we can then just get the first element out of the list.
first_face_location = face_locations[0]
To see what's in this, you can call:
print(first_face_location)
Which will print out something like:
(400, 1221, 862, 759)
These are the pixel positions for (top, right, bottom, left) which we will use to create a box and crop with soon.
Identifying The Detected Face
To identify where the face is that was detected in the image, we will draw a red box on the bounds that were returned by face_recognition.face_locations.
First, we need to create a PIL image from the image that was loaded using face_recognition.load_image_file. Doing this will allow us to use features offered by PIL.
img = Image.fromarray(image, 'RGB')
Now that we have the PIL image, we need to create an object to help us draw on the image. Before we do this, we will also copy the image into a new object so that when we crop the face out later there won't be a red box still around it.
img_with_red_box = img.copy()
img_with_red_box_draw = ImageDraw.Draw(img_with_red_box)
Now that we have an object to help us draw on the image, we will draw a rectangle using the dimensions returned earlier.
To draw a box, we need two points, the top left and the bottom right as x and y coordinates. Since we got back (top, right, bottom, left), we need to make these (left, top), (right, bottom); the basic translation can be seen below.
img_with_red_box_draw.rectangle(
[
(first_face_location[3], first_face_location[0]),
(first_face_location[1], first_face_location[2])
],
outline="red",
width=3
)
We needed
(left, top), (right, bottom)to get (x, y) (x, y) points.
In that step we have also set outline="red" to make the box red and width=3 to make the box 3 pixels wide.
To see the final result, we call:
img_with_red_box.show()
This will open the image in the default image viewer. The image should look like this:

Cropping Out The Detected Face
Aside from drawing a box, we can also crop out the face into another image.
Using the original image that we didn't draw on (because we drew on the copied image), we can call img.crop providing the dimensions from before.
img_cropped = img.crop((
first_face_location[3], # Left x
first_face_location[0], # Top y
first_face_location[1], # Right x
first_face_location[2] # Bottom y
))
img.cropreturns a copy of the original image being copped so you do not need to copy before-hand if you want to do something else with the original image.
img_cropped now contains a new cropped image, to display it, we can call .show() again.
img_cropped.show()

Final Code For This Section
import face_recognition
from PIL import Image, ImageDraw
# Detecting the faces
image = face_recognition.load_image_file('single-person.jpg') # Load the image
face_locations = face_recognition.face_locations(image) # Detect the face locations
first_face_location = face_locations[0] # Get the first face
# Convert the face_recognition image to a PIL image
img = Image.fromarray(image, 'RGB')
# Creating the image with red box
img_with_red_box = img.copy() # Create a copy of the original image so there is not red box in the cropped image later
img_with_red_box_draw = ImageDraw.Draw(img_with_red_box) # Create an image to draw with
img_with_red_box_draw.rectangle( # Draw the rectangle on the image
[
(first_face_location[3], first_face_location[0]), # (left, top)
(first_face_location[1], first_face_location[2]) # (right, bottom)
],
outline="red", # Make the box red
width=3 # Make the box 3px in thickness
)
img_with_red_box.show() # Open the image in the default image viewer
# Creating the cropped image
img_cropped = img.crop(( # Crop the original image
first_face_location[3],
first_face_location[0],
first_face_location[1],
first_face_location[2]
))
img_cropped.show() # Open the image in the default image viewer
Detecting Multiple Faces In An Image
We saw before that face_recognition.face_locations returns an array of tuples corresponding with the locations of faces. This means we can use the same methods above, but loop over the result of face_recognition.face_locations when drawing and cropping.
I will use the following as my image. It has 5 faces visible, 2 of which are slightly blurred.

Once again, we want to import face_recognition and some helpers from PIL.
import face_recognition
from PIL import Image, ImageDraw
Then load the new image using face_recognition.load_image_file and detect the faces using the same methods as before.
image = face_recognition.load_image_file('group-of-people.jpg')
face_locations = face_recognition.face_locations(image)
If we print out face_locations (print(face_locations)), we can see that 5 faces have been detected.
[
(511, 1096, 666, 941),
(526, 368, 655, 239)
(283, 1262, 390, 1154),
(168, 1744, 297, 1615),
(271, 390, 378, 282)
]
Since we now have more than one face, taking the first one does not make sense - we should loop over them all and perform our operations in the loop.
Before we continue, we should also create the PIL image we will be working with.
img = Image.fromarray(image, 'RGB')
Identifying The Detected Faces
Like before, we need to copy the original image for later (optional) and create an object to help us draw.
img_with_red_box = img.copy()
img_with_red_box_draw = ImageDraw.Draw(img_with_red_box)
Now we can loop all the faces and create rectangles.
for face_location in face_locations:
img_with_red_box_draw.rectangle(
[
(face_location[3], face_location[0]),
(face_location[1], face_location[2])
],
outline="red",
width=3
)
And once again, look at the image:
img_with_red_box.show()

Not bad eh!
Cropping Out The Detected Faces
Just like drawing many boxes, we can also crop all the detected faces. Use a for-loop again, crop the image in each loop and then showing the image.
for face_location in face_locations:
img_cropped = img.crop((face_location[3], face_location[0], face_location[1], face_location[2]))
img_cropped.show()
You will have many images open on your machine in separate windows; here they are all together:





I have downscaled these images for the tutorial but yours will be cropped at whatever resolution you put in.
Final Code For This Section
import face_recognition
from PIL import Image, ImageDraw
# Load image and detect faces
image = face_recognition.load_image_file("group-of-people.jpg")
face_locations = face_recognition.face_locations(image)
# Create the PIL image to copy and crop
img = Image.fromarray(image, 'RGB')
img_with_red_box = img.copy() # Make a single copy for all the red boxes
img_with_red_box_draw = ImageDraw.Draw(img_with_red_box) # Get our drawing object again
for face_location in face_locations: # Loop over all the faces detected this time
img_with_red_box_draw.rectangle( # Draw a rectangle for the current face
[
(face_location[3], face_location[0]),
(face_location[1], face_location[2])
],
outline="red",
width=3
)
img_with_red_box.show() # Open the image in the default image viewer
for face_location in face_locations: # Loop over all the faces detected
img_cropped = img.crop(( # Crop the current image like we did last time
face_location[3],
face_location[0],
face_location[1],
face_location[2]
))
img_cropped.show() # Show the image for the current iteration
Identifying Facial Features
face_recognition also has a function face_recognition.face_landmarks which works like face_recognition.face_locations but will return a list of dictionaries containing face feature positions rather than the positions of the detected faces themselves.
Going back to the image with one person in it, we can import everything again, load the image and call face_recognition.face_landmarks.
import face_recognition
from PIL import Image, ImageDraw
image = face_recognition.load_image_file('single-person.jpg')
face_landmarks_list = face_recognition.face_landmarks(image) # The new call
Now if we print face_landmarks_list, the object will look a bit different.
[
{
'chin': [(315, 223), (318, 248), (321, 273), (326, 296), (335, 319), (350, 339), (370, 354), (392, 365), (415, 367), (436, 363), (455, 351), (469, 336), (479, 318), (486, 296), (488, 273), (490, 251), (489, 229)],
'left_eyebrow': [(329, 194), (341, 183), (358, 180), (375, 182), (391, 189)],
'right_eyebrow': [(434, 189), (448, 184), (461, 182), (474, 184), (483, 194)],
'nose_bridge': [(411, 209), (411, 223), (412, 238), (412, 253)],
'nose_tip': [(394, 269), (403, 272), (412, 275), (421, 272), (428, 269)],
'left_eye': [(349, 215), (360, 208), (373, 207), (384, 216), (372, 218), (359, 219)],
'right_eye': [(436, 216), (446, 208), (458, 208), (467, 216), (459, 219), (447, 219)],
'top_lip': [(374, 309), (388, 300), (402, 296), (411, 298), (420, 296), (434, 301), (448, 308), (442, 308), (420, 307), (411, 308), (402, 307), (380, 309)],
'bottom_lip': [(448, 308), (434, 317), (421, 321), (411, 322), (401, 321), (388, 317), (374, 309), (380, 309), (402, 309), (411, 310), (421, 309), (442, 308)]
}
]
There is quite a bit of stuff here. For each facial feature (i.e. chin, left eyebrow, right eyebrow, etc), a corresponding list contains x and y tuples - these x and y points are x and y coordinates on the image.
PIL offers a .line() method on the drawing object we have been uses which takes a list of x and y points which is perfect for this situation. To start we will need a drawing object.
img = Image.fromarray(image, 'RGB') # Make a PIL image from the loaded image
img_draw = ImageDraw.Draw(img) # Create the draw object
In this example we will not copy the image as this is the only time we will be using it
Now that we have the object to help us draw, plot all these lines using the first dictionary in the list returned above.
face_landmarks = face_landmarks_list[0] # Get the first dictionary of features
img_draw.line(face_landmarks['chin'])
img_draw.line(face_landmarks['left_eyebrow'])
img_draw.line(face_landmarks['right_eyebrow'])
img_draw.line(face_landmarks['nose_bridge'])
img_draw.line(face_landmarks['nose_tip'])
img_draw.line(face_landmarks['left_eye'])
img_draw.line(face_landmarks['right_eye'])
img_draw.line(face_landmarks['top_lip'])
img_draw.line(face_landmarks['bottom_lip'])
Now we can call .show() on our image to look at it:
img_draw.show()

Final Code For This Section
import face_recognition
from PIL import Image, ImageDraw
# Load the image and detect face landmarks for each face within
image = face_recognition.load_image_file('single-person.jpg')
face_landmarks_list = face_recognition.face_landmarks(image)
# Make a PIL image from the loaded image and then get a drawing object
img = Image.fromarray(image, 'RGB')
img_draw = ImageDraw.Draw(img)
# Draw all the features for the first face
face_landmarks = face_landmarks_list[0] # Get the first object corresponding to the first face
img_draw.line(face_landmarks['chin'])
img_draw.line(face_landmarks['left_eyebrow'])
img_draw.line(face_landmarks['right_eyebrow'])
img_draw.line(face_landmarks['nose_bridge'])
img_draw.line(face_landmarks['nose_tip'])
img_draw.line(face_landmarks['left_eye'])
img_draw.line(face_landmarks['right_eye'])
img_draw.line(face_landmarks['top_lip'])
img_draw.line(face_landmarks['bottom_lip'])
img_with_face_landmarks.show() # Show the image for the current iteration
Matching Detected Faces
The face_recognition library also provides the function face_recognition.compare_faces which can be used to compare detected faces to see if they match.
There are two arguments for this function which we will use:
known_face_encodings: A list of known face encodingsface_encoding_to_check: A single face encoding to compare against the list
For this section, we will be getting 2 face encodings for the same person and checking if they are in another image.
Here are the two images with a known face in each:


elon-musk-1.jpg elon-musk-2.png
And here are the images we will check to see if Elon is in them:

elon-musk-in-group.jpg group-of-people.jpg
Getting Face Encodings
To get known face encodings, we can use face_recognition.face_encodings. This function takes an image that contains a face and the locations of faces in images to use.
Typically you would only use one location of a face in a single image to create one encoding but if you have multiple of the same face in one image you can provide more than one location.
The process of what we need to do to get our known face encodings is:
- Load in the first image
- Detect faces in the image to get the face locations
- Verify there is only one face and select the first face
- Call
face_recognition.face_encodingswith the image and the one face location - Repeat 1 through 5 for the second image
We have done steps 1-3 previously, so we can do it here again:
import face_recognition
# Load image and detect faces
image = face_recognition.load_image_file("elon-musk-1.jpg")
face_locations = face_recognition.face_locations(image)
And to validate one face was detected:
print(len(face_locations)) # Should be 1
Now we can call face_recognition.face_encodings and provide the image and found location.
face_location = face_locations[0] # We only want an encoding for the first face. There may be more than one face in images you use so I am leaving this here as a note.
face_encodings = face_recognition.face_encodings(image, [face_location])
The parameter
known_face_locationsis optional and face_recognition will detect all the faces in the image automatically when getting face encodings ifknown_face_locationsis not supplied. For this part, I am demonstrating it this way to validate there is only one detected face in the image.
Since we specified an array of known_face_locations, we know that there will be only one encoding returned so we can take the first.
elon_musk_knwon_face_encoding_1 = face_encodings[0]
We can now repeat this process for the other image
image = face_recognition.load_image_file("elon-musk-2.png") # Load the image
face_locations = face_recognition.face_locations(image) # Get face locations
face_location = face_locations[0] # Only use the first detected face
face_encodings = face_recognition.face_encodings(image, [face_location]) # Get all face encodings
elon_musk_knwon_face_encoding_2 = face_encodings[0] # Pull out the one returned face encoding
Now that we have elon_musk_knwon_face_encoding_1 and elon_musk_knwon_face_encoding_2, we can see if they exist in our other two images.
Checking For Matches
To check for matches in an image with face_recognition.compare_faces, we need known face encodings (which we have just gotten above) and a single face encoding to check.
Since we are working with groups of images, we will have to loop the detected faces - although this will also work the same with only one person in the image.
First, we need to get all face decodings out of our first image to compare. I had noted above that the second parameter, known_face_locations, to face_recognition.face_encodings was optional, leaving it out will detect all faces in the image automatically and return face encodings for every face in the image; this is exactly what we want and will remove the intermediate step of detecting faces.
image = face_recognition.load_image_file("elon-musk-in-group.jpg") # Load the image we are comparing
unknwon_face_encodings = face_recognition.face_encodings(image) # Get face encodings for everyone in the image
Now that we have our unknown face encodings for all the faces in the group image, we can loop over them and check if either match:
for unknwon_face_encoding in unknwon_face_encodings:
matches = face_recognition.compare_faces(
[elon_musk_knwon_face_encoding_1, elon_musk_knwon_face_encoding_2], # The known face encodings (can be only 1 - less is faster)
unknwon_face_encoding # The single unknown face encoding
)
print(matches)
If you run this, you will see something like:
[True, True]
[False, False]
[False, False]
[False, False]
Each line is one comparison (stored in matches) and each boolean corresponds to a known face encoding and whether it matched the unknown face encoding.
From the values above, we can see that the first unknown face in the group image matched both known face encodings and the other three unknown faces didn't match either encoding. Using more than once face encoding can allow you to calculate a better probability but will cost you in speed.
If you run this on the other image, everything returns false.
Final Code For This Section
import face_recognition
# Load elon-musk-1.jpg and detect faces
image = face_recognition.load_image_file("elon-musk-1.jpg")
face_locations = face_recognition.face_locations(image)
# Get the single face encoding out of elon-musk-1.jpg
face_location = face_locations[0] # Only use the first detected face
face_encodings = face_recognition.face_encodings(image, [face_location])
elon_musk_knwon_face_encoding_1 = face_encodings[0] # Pull out the one returned face encoding
# Load elon-musk-2.jpg and detect faces
image = face_recognition.load_image_file("elon-musk-2.png")
face_locations = face_recognition.face_locations(image)
# Get the single face encoding out of elon-musk-2.jpg
face_location = face_locations[0]
face_encodings = face_recognition.face_encodings(image, [face_location])
elon_musk_knwon_face_encoding_2 = face_encodings[0]
# Load the image with unknown to compare
image = face_recognition.load_image_file("elon-musk-in-group.jpg") # Load the image we are comparing
unknwon_face_encodings = face_recognition.face_encodings(image)
# Loop over each unknwon face encoding to see if the face matches either known encodings
print('Matches for elon-musk-in-group.jpg')
for unknwon_face_encoding in unknwon_face_encodings:
matches = face_recognition.compare_faces(
[elon_musk_knwon_face_encoding_1, elon_musk_knwon_face_encoding_2], # The known face encodings (can be only 1 - less is faster)
unknwon_face_encoding # The single unknown face encoding
)
print(matches)
# Load the other image with unknown to compare
image = face_recognition.load_image_file("group-of-people.jpg") # Load the image we are comparing
unknwon_face_encodings = face_recognition.face_encodings(image)
# Loop over each unknwon face encoding to see if the face matches either known encodings
print('Matches for group-of-people.jpg')
for unknwon_face_encoding in unknwon_face_encodings:
matches = face_recognition.compare_faces(
[elon_musk_knwon_face_encoding_1, elon_musk_knwon_face_encoding_2],
unknwon_face_encoding
)
print(matches)
Additional PIL Help
This tutorial doesn't focus on PIL but one function you may find useful is img.save(); this saves a file. An example of its usages is img.save('my_image.png') to save a PIL image to my_image.png.
You can find more on PIL in its docs and there is plenty of other help online as it is a very old library.