Earlier this year, I and seven other students were given a project to visualise emotion in music. We decided to use Unity for visualisation and machine learning in Python to detect emotion. After days of planning and testing, I had a plan for the emotion detection half.
The project can be found on GitHub here. While creating this program, I discovered a way that could give hints to what emotion the song is trying to portray using Spotify's API, some data mining and machine learning
Planning
I had discovered Spotify's API and found that you could get audio features of a particular song including features line loudness, tempo, duration and most importantly energy and valence.
In previous research, I had found a YouTube video that looked at emotion detection in music in realtime. Looking in other papers and similar creations like it, I had discovered that there were two things to make this plane; valence and energy. These two properties can be found under different names but in general, they stood for the musical positiveness given off by the song and the speed and intensity of the song.
Luckily Spotify had already calculated these values and due to it being such a big platform, I could rely on the data; unlike a lot of other sites I tested with. By simply querying "https://api.spotify.com/v1/audio-features/{id}" and passing an authorization token, I was given back data in JSON format.
An example of the JSON response can be found in the Spotify API documentation.
{
"danceability" : 0.735,
"energy" : 0.578,
"key" : 5,
"loudness" : -11.840,
"mode" : 0,
"speechiness" : 0.0461,
"acousticness" : 0.514,
"instrumentalness" : 0.0902,
"liveness" : 0.159,
"valence" : 0.624,
"tempo" : 98.002,
"type" : "audio_features",
"id" : "06AKEBrKUckW0KREUWRnvT",
"uri" : "spotify:track:06AKEBrKUckW0KREUWRnvT",
"track_href" : "https://api.spotify.com/v1/tracks/06AKEBrKUckW0KREUWRnvT",
"analysis_url" : "https://api.spotify.com/v1/audio-analysis/06AKEBrKUckW0KREUWRnvT",
"duration_ms" : 255349,
"time_signature" : 4
}
This meant all we needed to do was get the Spotify id for each song our program took in by looking at the tags the song had. I used mutagen to strip the tags of the .mp3 files and I then passed this to the search() method in the Spotipy library to get the Spotify id.
Gathering Data
The only piece left was now the data to compare each new song to. I had thought to scrape public Spotify playlist created by people with 'happy' and 'sad' in the titles. With all these songs, I then got their valence and energy and placed them on a plane. This process created the plane below.
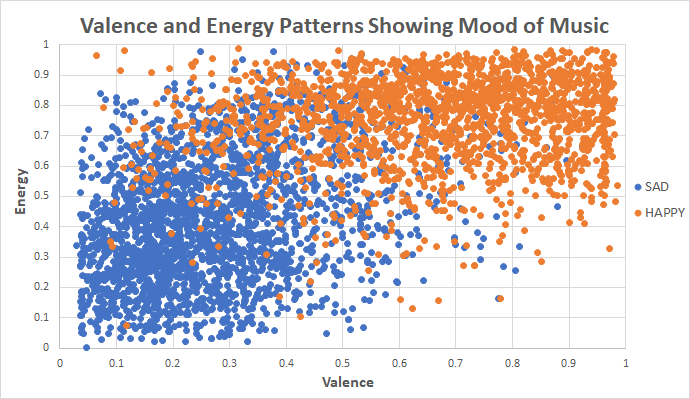
On initial investigation it appears that this plan had worked; and it did. Quite clearly we can see happy songs having high valence and energy where sadder songs have lower values of these properties. There is a bit of cross over which is fine but there are quite a few songs that are in the 'wrong' area. I investigated a few of the outliers and had found quite a majority of these songs were not really meant for the playlist I found them in.
I understood that using user-generated data could be unreliable but it was much more reliable than a computer doing it as people can detect emotion better than computers. Since I had used playlist generated by people we could rely on the data to quite an extent.
Python Code
Here are some quick examples of how I did the things mentioned in this article.
Getting Tags of MP3s
This code gets ID3 tags from MP3 files. To get mutagen, execute the command 'pip install mutagen' in a terminal/cmd.
from mutagen.id3 import ID3
from mutagen.mp3 import MP3
song_location = 'song.mp3'
audio = ID3(song_location)
title = audio['TIT2'].text[0]
artist = audio['TPE1'].text[0]
album = audio['TALB'].text[0]
Tags to Spotify ID
This code will search Spotify for the title and artist and return the closest Spotify ID. Note this will not always be 100% correct but Spotify has a large library of songs.
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
# Make your own Spotify app at https://beta.developer.spotify.com/dashboard/applications
client_id = ''
client_secret = ''
title = 'Clocks'
artist = 'Coldplay'
client_credentials_manager = SpotifyClientCredentials(client_id=client_id, client_secret=client_secret)
sp = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
sp.trace=False
search_querry = title + ' ' + artist
result = sp.search(search_querry)
for i in result['tracks']['items']:
# Find a songh that matches title and artist
if (i['artists'][0]['name'] == artist) and (i['name'] == title):
print (i['uri'])
break
else:
try:
# Just take the first song returned by the search (might be named differently)
print (result['tracks']['items'][0]['uri'])
except:
# No results for artist and title
print ("Cannot Find URI")
This example will return "spotify:track:0BCPKOYdS2jbQ8iyB56Zns" regarding you have provided a client_id and client_secret. This URI/ID relates to Clocks by Coldplay in Spotify's database.
Getting Audio Data
In the project I gathered audio data in blocks of 50; this example will only demonstrate one URI at a time. To get data of many songs at once pass a list of URI's to sp.audio_features().
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
# Make your own Spotify app at https://beta.developer.spotify.com/dashboard/applications
client_id = ''
client_secret = ''
uri = 'spotify:track:0BCPKOYdS2jbQ8iyB56Zns'
client_credentials_manager = SpotifyClientCredentials(client_id=client_id, client_secret=client_secret)
sp = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
sp.trace=False
features = sp.audio_features(uri)
print ('Energy:', features[0]['energy'])
print ('Calence:', features[0]['valence'])
This example should return: Energy: 0.749, Valence: 0.261
Conclusion
Using this data, I had created a Support Vector Machine with scikit-learn which then allowed us to provide a valence and energy value and be given a tag either as HAPPY or SAD back. Different playlists could have been provided to this project to make a different area of moods on the plane to give more variation in the moods returned.
In my opinion, this method worked quite well and was successful for our final project as it was able to detect emotion with high confidence. The method to compare valence and energy was later changed to scikit-learn's K Nearest Neighbours classifier on request of another student (their time delay).